YAMAHA RT1210 簡易内部DNSサーバに設定追加
上記ページに「静的DNSレコードの登録機能 (簡易DNSサーバ機能) 」というのがあったので設定してみる。
■書式
ip host fqdn value [ttl=ttl]
■設定例
ip host xxxx.mogumagu.com 192.168.3.100
RTX1210の管理画面にある「管理」⇒「コマンドの実行」で設定した。
天は自ら助くる者を助く
YAMAHA RT1210 簡易内部DNSサーバに設定追加
上記ページに「静的DNSレコードの登録機能 (簡易DNSサーバ機能) 」というのがあったので設定してみる。
■書式
ip host fqdn value [ttl=ttl]
■設定例
ip host xxxx.mogumagu.com 192.168.3.100
RTX1210の管理画面にある「管理」⇒「コマンドの実行」で設定した。
直したメモ。
namazuで全文検索を行っていたサイトで特定のワードで
検索結果画面にカタカナで「エラー!」と表示されてしまう現象に遭遇した。
事前の大量のファイルを削除したのでインデックスが壊れたのかと思って
色々と「mknmz」の設定を変更したけど解決しなかった。
最終的には「gcnmz」というコマンドを知り、ゴミを掃除してから
インデックスを再構築したら直った。
「gcnmz」したらmknmzもすっごい早くなった。
公式ではここにちょっとだけ紹介されていた。。
参考になったのは以下のページ
MountainBigRoad.JP 4 ) 文書の更新・削除に伴うインデックスの掃除
cronでmknmzしていたスクリプトにgcnmzも合わせて実行するように設定変更しておいた。
CentOS7、PHP7の環境にNextcloudをインストール
ファイル共有がしたくなったのでOSSを探した。
ownCloudがphpの関係で上手くインストールできなかったので
新しいっぽいnextcloudをインストールすることにする。
CentOS7、PHP7、Mariadbは設定済み
https://nextcloud.com/install/
↑のページの「Get Nextcloud Server」の「Download」をクリックして表示されたダイアログ内の「Download Nextcloud」の
URLをコピーしてwgetする。
# wget https://download.nextcloud.com/server/releases/nextcloud-12.0.0.zip # unzip nextcloud-12.0.0.zip # mv nextcloud /var/www/ # chown -R apache:apache /var/www/nextcloud
足りなかったので追加
# yum install --enablerepo=remi,remi-php70 php-pecl-zip
webサーバの設定追加
# pwd /etc/httpd/conf.d # cat nextcloud.conf Alias /nextcloud "/var/www/nextcloud/" <Directory /var/www/nextcloud/> Options +FollowSymlinks AllowOverride All <IfModule mod_dav.c> Dav off </IfModule> SetEnv HOME /var/www/nextcloud SetEnv HTTP_HOME /var/www/nextcloud </Directory>
webサーバ再起動
# systemctl restart httpd
http://ドメイン/nextcloud
にアクセス。
画面の誘導に沿って設定すればOK。
※MariaDBを使うようにした。
■参考URL
Azure上のCentOSにNextcloudを構築!!
さらばDropbox! 企業やチームのストレージにNextcloudが注目される理由
スクリーンリーダーの「NVDA」でFirefoxとChromeで「未定義」と出て読み上げられない人がいたので調査。
最終的に直ったのはこのコマンド
管理者権限でコマンドプロンプトを立ち上げて以下を入力。
C:\Windows\SysWOW64 regsvr32 oleacc.dll
※64bit版をインストールしているので「C:\Windows\SysWOW64」で実行しました。
Zabbixでapacheのコネクション数の監視
設定したときのメモ
監視対象のサーバのapacheの設定を変更する
# vim httpd.conf # diff httpd.conf_20160518 httpd.conf 912,917c912,917 < #<Location /server-status> < # SetHandler server-status < # Order deny,allow < # Deny from all < # Allow from .example.com < #</Location> --- > <Location /server-status> > SetHandler server-status > Order deny,allow > Deny from all > Allow from 127.0.0.1 > </Location>
ローカルホストからだけデータが取得できるように設定してリスタートする。
# service httpd restart httpd を停止中: [ OK ] httpd を起動中: [ OK ]
ステータスを確認する
# apachectl status The 'links' package is required for this functionality.
「elinks」が無いようなのでインストール
# yum install elinks
再度ステータスの確認
# apachectl status
Apache Server Status for localhost
Server Version: Apache
Server Built: Sep 16 2014 11:05:09
--------------------------------------------------------------------------
Current Time: Wednesday, 18-May-2016 17:11:39 JST
Restart Time: Wednesday, 18-May-2016 17:09:30 JST
Parent Server Generation: 0
Server uptime: 2 minutes 8 seconds
1 requests currently being processed, 7 idle workers
_W______........................................................
................................................................
................................................................
................................................................
Scoreboard Key:
"_" Waiting for Connection, "S" Starting up, "R" Reading Request,
"W" Sending Reply, "K" Keepalive (read), "D" DNS Lookup,
"C" Closing connection, "L" Logging, "G" Gracefully finishing,
"I" Idle cleanup of worker, "." Open slot with no current process
1 requests currently being processed, 7 idle workers
↑ここの部分が現在アクティブなリクエスト数をあらわしている
zabbix_agentのユーザパラメータの設定
# pwd
/etc/zabbix
# vim zabbix_agentd.conf
末尾に「UserParameter=apache.con.num,/usr/sbin/apachectl status|grep "requests currently being processed"|awk '{print $1}'」を追加する
# diff zabbix_agentd.conf_20160518 zabbix_agentd.conf
268a269
> UserParameter=apache.con.num,/usr/sbin/apachectl status|grep "requests currently being processed"|awk '{print $1}'
# service zabbix-agent restart
Shutting down zabbix agent: [ OK ]
Starting zabbix agent: [ OK ]
ここまでできたらzabbixの管理画面で設定を行う。
「設定」⇒「ホスト」⇒今回設定を行ったホストの「アイテム」をクリック。
画面右上の「アイテムの作成」でapache.con.numをキーとして設定する。
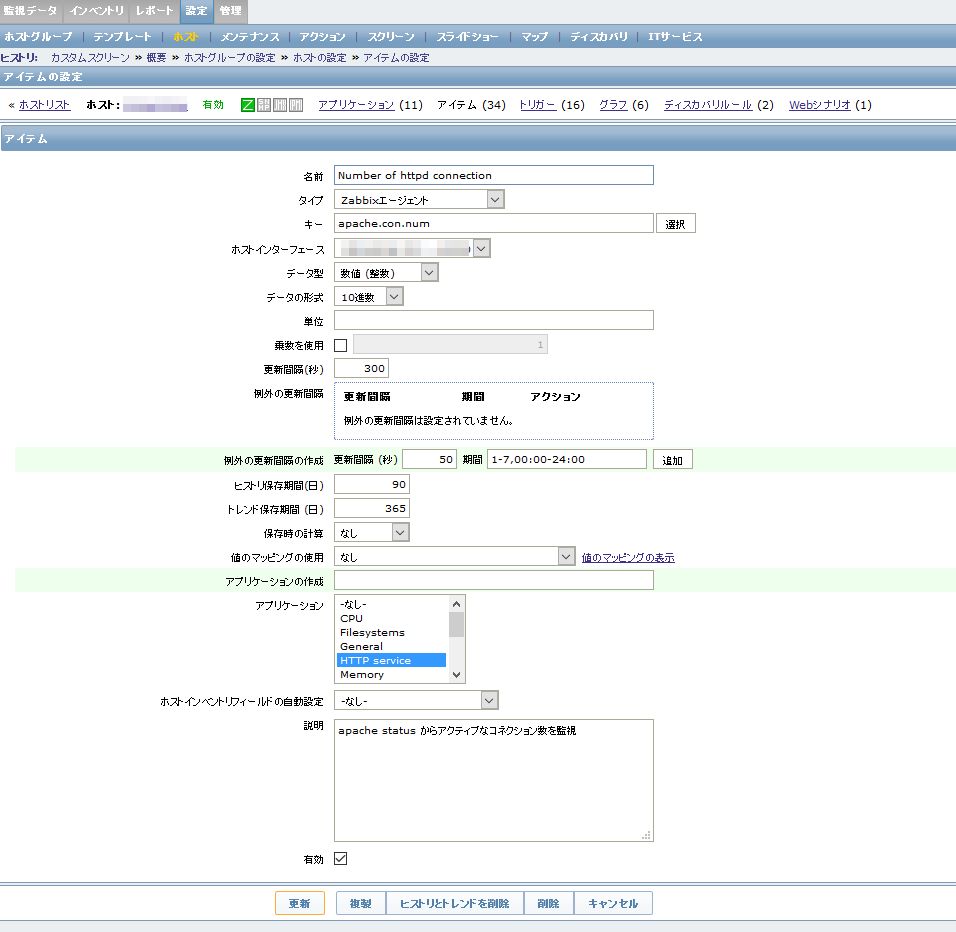
しかし設定しても値が入ってこない・・・。
ホスト側のログをみてみると以下のようなエラーが!
# less /var/log/zabbix/zabbix_agentd.log ^GERROR at home.c:149: Unable to find or create ELinks config directory. Please check if you have $HOME variable set correctly and if you have write permission to your home directory.
どうも「apachectl」のlinksコマンドがホームディレクトリに書き込め無くて出るエラーらしいので「apachectl」自体をコピーして
オプションを追加し、「zabbix_agentd.conf」ではそっちの「apachectl」を利用すればいいみたいです。
[root@www15172u sbin]# pwd
/usr/sbin
とりあえず「apachectl2」とする
[root@www15172u sbin]# cp apachectl apachectl2
[root@www15172u sbin]# vim apachectl2
[root@www15172u sbin]# diff apachectl apachectl2
51c51
< LYNX="/usr/bin/links -dump" --- > LYNX="/usr/bin/links -dump -no-home"
# vim /etc/zabbix/zabbix_agentd.conf
UserParameter=apache.con.num,/usr/sbin/apachectl2 status|grep "requests currently being processed"|awk '{print $1}'
# service zabbix-agent restart
Shutting down zabbix agent: [ OK ]
Starting zabbix agent: [ OK ]
しばらく待つと・・・。

でた。
■参考ページ
zabbix-agentでapachectlからデータを取得するUserParameterを設定したらコケた
# pwd /etc/httpd/conf.d/vhost # cat localhost.conf <VirtualHost *:80> ServerName localhost DocumentRoot /var/www/html <Location /server-status> SetHandler server-status Order deny,allow Deny from all Allow from localhost </Location> </VirtualHost>
■CentOS7のApacheではsutatusではなくfullstatusにする
# apachectl fullstatus
設定に記載するのは↓
UserParameter=apache.con.num,/usr/sbin/apachectl2 fullstatus|grep "requests currently being processed"|awk '{print $1}'
■上記設定をしてzabbix-agentを再起動するもログにこんなエラーが出てしまった。
listener failed: zbx_tcp_listen() fatal error: unable to serve on any address [[-]:10050]
以前のプロセスが残っているようなのでまず止めてみる。
■サービスを止める。でもとまらなかった・・・
# systemctl stop zabbix-agent.service
■zabbix-agentのプロセスを探す
# ps -ef |grep zabbix
■zabbix-agentのプロセスを殺す
# systemctl kill --signal=9 zabbix-agent
■zabbix-agentを起動する
# systemctl start zabbix-agent.service
同僚のThunderbirdで受信したメールの一部で文字化けが発生した。
もう少し具体的に症状を書くと、
・新しく受信したメールは正常にみれる
・受信一覧で添付ファイル付きメールを選択すると添付アイコンが消える
・以前受信したメールで受信一覧からクリックしてメールを開くと件名が空になり本文が文字化けしている
・そもそも一覧の件名が合っているかちょっと不明
・文字化けしているがどうも本文中にメールヘッダがちぎれて表示されているような感じ
・メールのソースを見てみるとFromから始まっていない状態
Thunderbirdを最新版(38.7.0)にしたとかNortonでセキュリティスキャンしてたとか
色々な状況が重なってたようですが、調べてみるとこれは要約ファイルが破損したことが
原因っぽいので対応してみる。
※事前にアドオンの無効化とか一通り試しています。
※以下の方法は自己責任でお願いします。
まずメッセージの保存先を調べるために
「ツール」⇒「アカウント設定」⇒「サーバ設定」⇒「メッセージの保存先」のパスをコピーする。
次にThunderbirdを終了させる。
終了させたらメッセージの保存先フォルダに移動して、フォルダ内にある末尾が「~.msf」の
ファイルをすべて適当なフォルダにバックアップをとって削除する。
「Inbox.sbd」内にも「.msf」ファイルがあるので全てバックアップをとってから削除する。
いっぱいあるかもしれないけど、どの要約ファイルが壊れているのかわからないので
「~.msf」はとりあえず全部削除する。
「~.msf」で無いファイルは本データらしいので消さないように注意!
削除が終わったらThunderbirdを起動する。
これで同僚のThunderbirdは直りました。
CentOS7にMondo Rescureをインストール
Mondo Rescureを使ってみようと思いローカル環境で実験をすることに。
最終目標はさくらのVPSのリカバリディスクの作成。
今回の実験環境
ホスト:Windows10
VirtualBox:5.0.12
Vagrant:1.8.1
ゲスト:CentOS7.2
ゲストのCentOS7.2のリカバリディスクを作成する。
※Vagrant環境なんだからpackageにすればいいんだけど「Mondo Rescure」の実験なので・・・。
作業はゲストでのみ行う。
まずはCentOS7.2にログインしてインストールから。
■yumリポジトリをインストールして「Mondo Rescure」をインストールする。
ミラーサイトからリポジトリを取得
# wget ftp://mondo.mirror.pclark.com/pub/mondorescue/rhel/7/x86_64/mondorescue.repo # mv mondorescue.repo /etc/yum.repos.d/
■インストール
# yum --enablerepo=mondorescue search mondo Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile * base: www.ftp.ne.jp * epel: ftp.riken.jp * extras: www.ftp.ne.jp * remi-php70: mirrors.thzhost.com * remi-safe: mirrors.thzhost.com * updates: www.ftp.ne.jp ============================================================================================================ N/S matched: mondo ============================================================================================================= mondo.x86_64 : MondoRescue is a GPL Disaster Recovery and Cloning Solution mondo-debuginfo.x86_64 : Debug information for package mondo perl-MondoRescue.noarch : The perl-MondoRescue provides a set of functions for the MondoRescue project # yum --enablerepo=mondorescue install mondo ・・・・ Complete!
以上でインストールは完了。
2つのコマンドが入った模様
mondoarchive
mondorestore
■バージョン確認
# mondoarchive -v mondoarchive v3.2.1-r3456 See man page for help
■ISOイメージを作成してみる
オプションはこのページを参考にしました。
# mondoarchive -Oi -s 4480m -d /tmp See /var/log/mondoarchive.log for details of backup run. Checking sanity of your Linux distribution Done. Making catalog of files to be backed up ---evalcall---1--- Making catalog of / ---evalcall---2--- TASK: [**..................] 10% done; 0:09 to go ---evalcall---E--- ---evalcall---1--- Making catalog of / ---evalcall---2--- TASK: [**********..........] 48% done; 0:02 to go ---evalcall---E--- ---evalcall---1--- Making catalog of / ---evalcall---2--- TASK: [***********.........] 53% done; 0:02 to go ---evalcall---E--- ---evalcall---1--- Making catalog of / ---evalcall---2--- TASK: [***************.....] 71% done; 0:01 to go ・・・・・ ---evalcall---1--- Verifying... ---evalcall---2--- TASK: [******..............] 28% done; 0:02 to go ---evalcall---E--- ---evalcall---1--- Verifying... ---evalcall---2--- TASK: [**********..........] 50% done; 0:06 to go ---evalcall---E--- Mindi failed to create your boot+data disks. Fatal error... Failed to generate boot+data disks ---FATALERROR--- Failed to generate boot+data disks If you require technical support, please contact the mailing list. See http://www.mondorescue.org for details. The list's members can help you, if you attach that file to your e-mail. Log file: /var/log/mondoarchive.log Mondo has aborted. rm: cannot remove ‘/tmp/mondo.tmp.OD9jow/mountpoint.29356’: Device or resource busy Execution run ended; result=254 Type 'less /var/log/mondoarchive.log' to see the output log
こけた?
Mondo RescueをつかってのCentOs7のバックアップ
上記のページを参考に設定値を変更してみた。
# pwd /etc/mindi # diff mindi.conf.org mindi.conf 12,13c12,13 < # EXTRA_SPACE=80152 # increase if you run out of ramdisk space < # BOOT_SIZE=32768 # size of the boot disk --- > EXTRA_SPACE=240000 # increase if you run out of ramdisk space > BOOT_SIZE=100000 # size of the boot disk
なんとなく出力先も変更して再度実行
# mondoarchive -Oi -s 4480m -d /backup -E /backup ・・・ ---progress-form---3--- Please wait. This may take some time. ---progress-form---E--- ---progress-form---4--- TASK: [********************] 100% done; 0:00 to go Done. Writing any remaining data to media Please be patient. Do not be alarmed by on-screen inactivity. Call to mkisofs to make ISO (ISO #1) ...OK Done. Done. Backup and/or verify ran to completion. Everything appears to be fine. /var/cache/mindi/mondorescue.iso, a boot/utility CD, is available if you want it Data archived OK. Mondoarchive ran OK. See /var/log/mondoarchive.log for details of backup run. Execution run ended; result=0 Type 'less /var/log/mondoarchive.log' to see the output log
出来た!
# pwd /backup # ls -alh total 1.2G drwxr-xr-x 2 root root 30 Jan 28 06:40 . dr-xr-xr-x. 19 root root 4.0K Jan 28 06:20 .. -rw-r--r-- 1 root root 1.2G Jan 28 06:40 mondorescue-1.iso
isoイメージは1.2GBになった。
そもそもこのサーバの使用容量はこちら↓
# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 8.3G 4.2G 4.1G 51% / devtmpfs 298M 0 298M 0% /dev tmpfs 308M 0 308M 0% /dev/shm tmpfs 308M 4.5M 304M 2% /run tmpfs 308M 0 308M 0% /sys/fs/cgroup /dev/sda1 497M 230M 267M 47% /boot tmpfs 62M 0 62M 0% /run/user/1000
■isoが出来たのでリカバリの実験
これは参考サイト「Mondo rescueを用いたシステムリカバリの方法」
と同様にVirtualBoxにisoイメージをセットして起動し、Automaticallyで実行した。
参考サイトの指示通りにやってたリカバリができた。
あとはネットワークの設定とかをやってみたらそっくりそのままの環境ができた。
ローカルでの実験ができたので稼働中のさくらVPSとかでも実行する予定。
■参考サイト
Mondo Rescue Home Page
ローカルにインストールしているJIRAが落ちた際の対応
JIRAをローカルインストールして使ったいたらいきなりJIRAが落ちた。
ログファイルを探してみてみると↓こんなエラーが・・・。
ログファイルの場所:/opt/atlassian/jira/logs/catalina.2015-11-19.log
11 19, 2015 3:16:57 午後 org.apache.catalina.startup.ContextConfig processAnnotationsFile
重大: Unable to process file [/opt/atlassian/jira/atlassian-jira/WEB-INF/classes/com/atlassian/jira/scheme/DefaultSchemeFactory.class] for annotations
java.io.FileNotFoundException: /opt/atlassian/jira/atlassian-jira/WEB-INF/classes/com/atlassian/jira/scheme/DefaultSchemeFactory.class (システム中のファイルを開きすぎです)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at org.apache.catalina.startup.ContextConfig.processAnnotationsFile(ContextConfig.java:2032)
at org.apache.catalina.startup.ContextConfig.processAnnotationsFile(ContextConfig.java:2026)
at org.apache.catalina.startup.ContextConfig.processAnnotationsFile(ContextConfig.java:2026)
at org.apache.catalina.startup.ContextConfig.processAnnotationsFile(ContextConfig.java:2026)
at org.apache.catalina.startup.ContextConfig.processAnnotationsFile(ContextConfig.java:2026)
at org.apache.catalina.startup.ContextConfig.webConfig(ContextConfig.java:1291)
at org.apache.catalina.startup.ContextConfig.configureStart(ContextConfig.java:876)
at org.apache.catalina.startup.ContextConfig.lifecycleEvent(ContextConfig.java:374)
at org.apache.catalina.util.LifecycleSupport.fireLifecycleEvent(LifecycleSupport.java:117)
at org.apache.catalina.util.LifecycleBase.fireLifecycleEvent(LifecycleBase.java:90)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5378)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:150)
at org.apache.catalina.core.ContainerBase$StartChild.call(ContainerBase.java:1575)
at org.apache.catalina.core.ContainerBase$StartChild.call(ContainerBase.java:1565)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
「Too many open files」のエラーだと思うのでそれ関連で調べてみる。
Linux サーバでの「Too many open files」対策について
http://d.hatena.ne.jp/akishin999/20130213/1360711554
上記のサイトにたどり着いた。
今回のサーバはOpenVZで運用している「CentOS6.5」でulimitは↓の状態でした。
# ulimit -n 1024
ブログにあるとおり「/etc/sysconfig/init」の最後に追記する方法を実行。
ulimit -n 65536
で、OSをリブート。
# ulimit -n 65536
変わった!
ローカル環境なのでとりあえずこれでOK。JIRAも快調に動いてます。
ZabbixからSlackに通知する
いまさらながら社内でSlackが流行りだしています。
というわけで、練習がてらzabbixからの障害通知をslackに出してみる。
以下のスクリプトを利用。
ericoc/zabbix-slack-alertscript
Zabbix Slack AlertScript
https://github.com/ericoc/zabbix-slack-alertscript
設定もほぼそのまま。
で、実際に障害を起こしてみるとこんなメッセージが!

簡単にできた!
やったことのメモ。
(12)Cannot allocate memory: fork: Unable to fork new process
が発生したので調査のためにスクリプトを追加。
発生までの経緯をみるとどうもswapが徐々に喰いつぶされていき、swapが無くなると
上記のエラーが発生しているような感じ。
徐々にといっても何らかのタイミングでガクンとswapが減るのでそれをどうにか
突き止めたい。。。
いろいろ調べて以下のページを参考にしてスクリプトを作成(そのまま)
Find Out What Is Using Your Swap
http://northernmost.org/blog/find-out-what-is-using-your-swap/
/proc/以下のプロセスのフォルダ内のsmaps内をさらって合計していく感じ。
■getswap.sh
#!/bin/bash
# Get current swap usage for all running processes
# Erik Ljungstrom 27/05/2011
SUM=0
OVERALL=0
for DIR in `find /proc/ -maxdepth 1 -type d | egrep "^/proc/[0-9]"` ; do
PID=`echo $DIR | cut -d / -f 3`
PROGNAME=`ps -p $PID -o comm --no-headers`
for SWAP in `grep Swap $DIR/smaps 2>/dev/null| awk '{ print $2 }'`
do
let SUM=$SUM+$SWAP
done
echo "PID=$PID - Swap used: $SUM - ($PROGNAME )"
let OVERALL=$OVERALL+$SUM
SUM=0
done
echo "Overall swap used: $OVERALL"
■cronswap.sh
クーロンで叩く用。
#!/bin/bash
FILENAME=`date +"%Y%m%d_%H%M%S"`
echo "${FILENAME}"
/root/swapLog/getswap.sh | egrep -v "Swap used: 0" |sort -n -k 5 > /root/swapLog/log/"${FILENAME}".log
■logs
このフォルダに日時の形式で出力
■cronの設定
1ファイル2KB程度なのでとりあえずとりっぱなしで。10分毎。
#swaplog
*/10 * * * * /root/swapLog/cronswap.sh
■設置時のswap出力例
swapを使ってるプロセスが表示される。
$ less 20150914_162958.log
Overall swap used: 123388
PID=1840 - Swap used: 28 - (syslogd )
PID=2245 - Swap used: 28 - (saslauthd )
PID=2247 - Swap used: 28 - (saslauthd )
PID=2248 - Swap used: 28 - (saslauthd )
PID=2244 - Swap used: 32 - (saslauthd )
PID=2246 - Swap used: 32 - (saslauthd )
PID=1843 - Swap used: 44 - (klogd )
PID=2328 - Swap used: 48 - (mingetty )
PID=2323 - Swap used: 52 - (mingetty )
PID=2332 - Swap used: 52 - (mingetty )
PID=2307 - Swap used: 56 - (gam_server )
PID=2324 - Swap used: 56 - (mingetty )
PID=2330 - Swap used: 56 - (mingetty )
PID=2329 - Swap used: 60 - (mingetty )
PID=1 - Swap used: 64 - (init )
・・・・
PID=2274 - Swap used: 148 - (hald-runner )
PID=9940 - Swap used: 148 - (pop3-login )
PID=2054 - Swap used: 152 - (mysqld_safe )
PID=2017 - Swap used: 224 - (vsftpd )
PID=496 - Swap used: 260 - (udevd )
PID=1962 - Swap used: 304 - (sshd )
PID=1901 - Swap used: 448 - (3dm2 )
PID=1914 - Swap used: 448 - (3dm2 )
PID=1915 - Swap used: 448 - (3dm2 )
PID=2273 - Swap used: 1900 - (hald )
PID=2320 - Swap used: 7172 - (miniserv.pl )
PID=1804 - Swap used: 7468 - (miniserv.pl )
PID=17177 - Swap used: 7736 - (spamd )
PID=17197 - Swap used: 8364 - (spamd )
PID=2303 - Swap used: 10060 - (yum-updatesd )
PID=2158 - Swap used: 24512 - (spamd )
PID=2101 - Swap used: 44588 - (mysqld )
あと合わせてsarコマンドも設定
参考
http://blog.ybbo.net/2013/07/10/oom-killer%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6/
http://b.l0g.jp/dev/finding-bottleneck-with-sar1/
http://b.l0g.jp/dev/finding-bottleneck-with-sar2/
pstreeも確認するようにする。
$ pstree -lcph
http://itpro.nikkeibp.co.jp/article/COLUMN/20071204/288730/
またアクセスログの記録と対応するようにApacheのaccess_logの先頭にPIDを表示するように設定を変更した。
「%P」はPIDを出力する。先頭に追加。
これでswapを確保したままになっているのがhttpのプロセスだった場合にどのアクセスと対応しているのか
がわかるはず。
$ diff httpd.conf httpd.conf_back20150914
485,486c485,486
< LogFormat "%P %h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
< LogFormat "%P %h %l %u %t \"%r\" %>s %b" common
---
> LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
> LogFormat "%h %l %u %t \"%r\" %>s %b" common
再起動必須。
実際「Cannot allocate memory」が出て已む無くapacheをリスタートしようと
したのに起動に失敗したときの対応は以下。
#service httpd restart 失敗した! #/usr/sbin/lsof -i | grep http 開いているファイルのプロセスを特定 #kill-9 プロセスID そのほかのプロセスも殺す。 #service httpd start
後はswapの残りを監視してアラート飛ばすのを作る予定。